The use of personal data by web platforms has always been a slippery slope. In order to justify their ad-supported business strategy to users, Big Tech's marketing departments manufactured the ostensible benefit of "personalization" in return for the capturing, re-use, and re-selling of personal data. The conceit was, they are going to show you ads and targeted posts no matter what, but at least those interruptions might be more in line with your interests.
This already feels invasive when it comes to capturing what you are interacting with, which groups you are in, which keywords in text are most likely to compel your engagement, and so on. It's an extraction of user intent.
What happens when the system is capturing more than your clicks though? When you are talking to an AI, or working with it to create content, where is the line drawn between what belongs to you, what belongs to the platform, and what to do with the stuff in the middle?
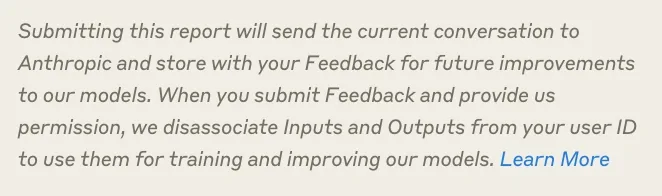
While the nuances and principles of this market are ironed out, many AI companies have implemented the Data Retention pattern, leading to its near ubiquity.

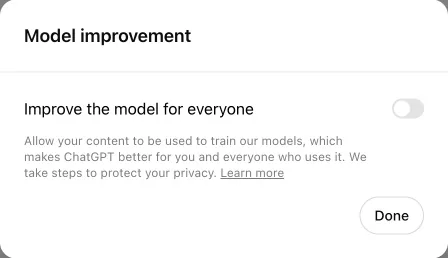
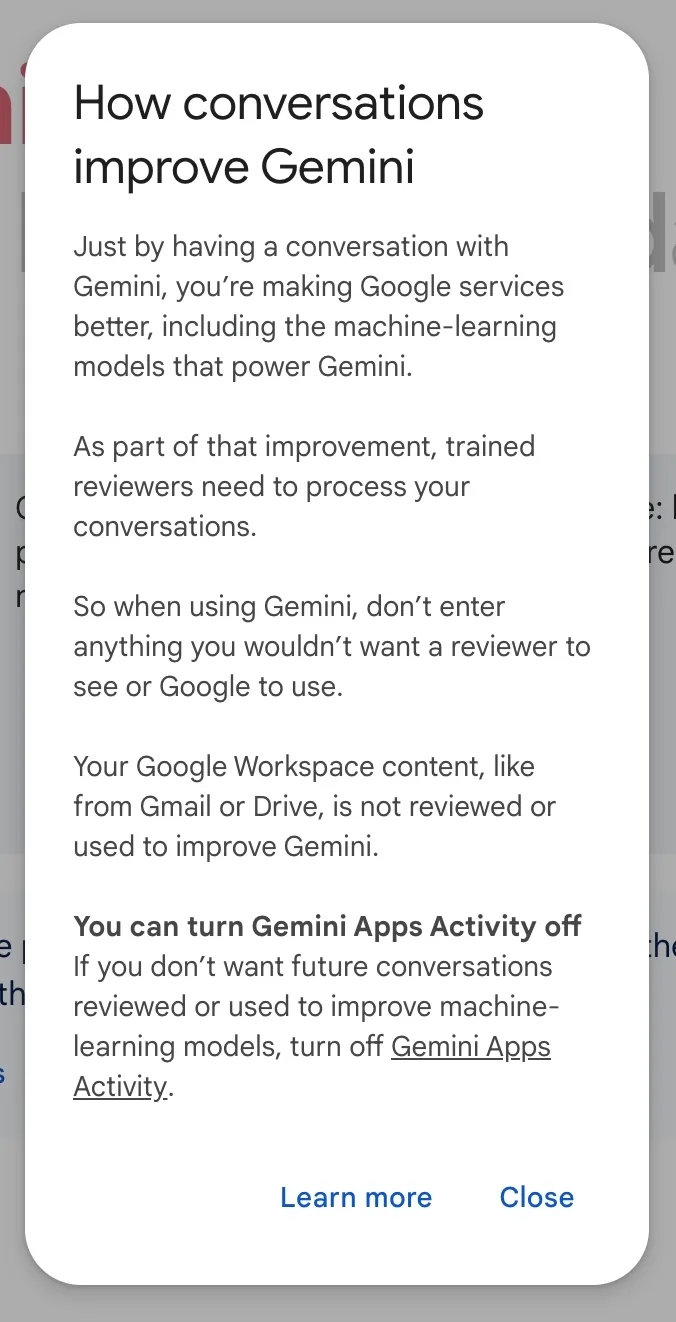
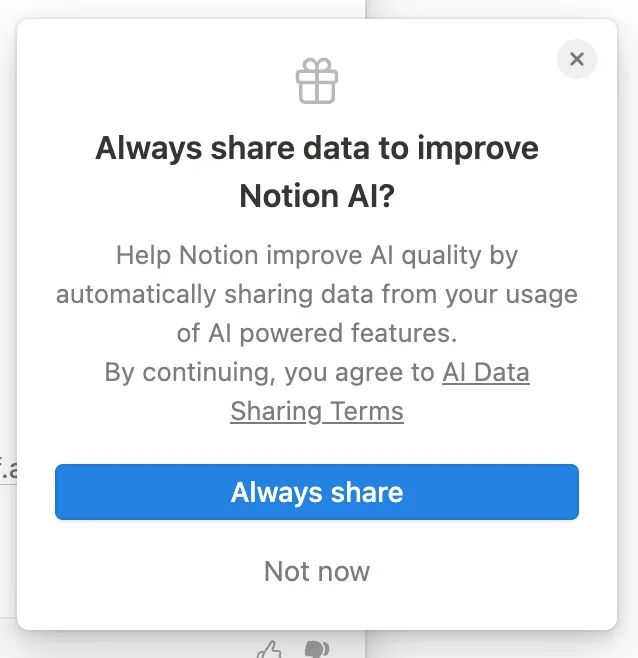
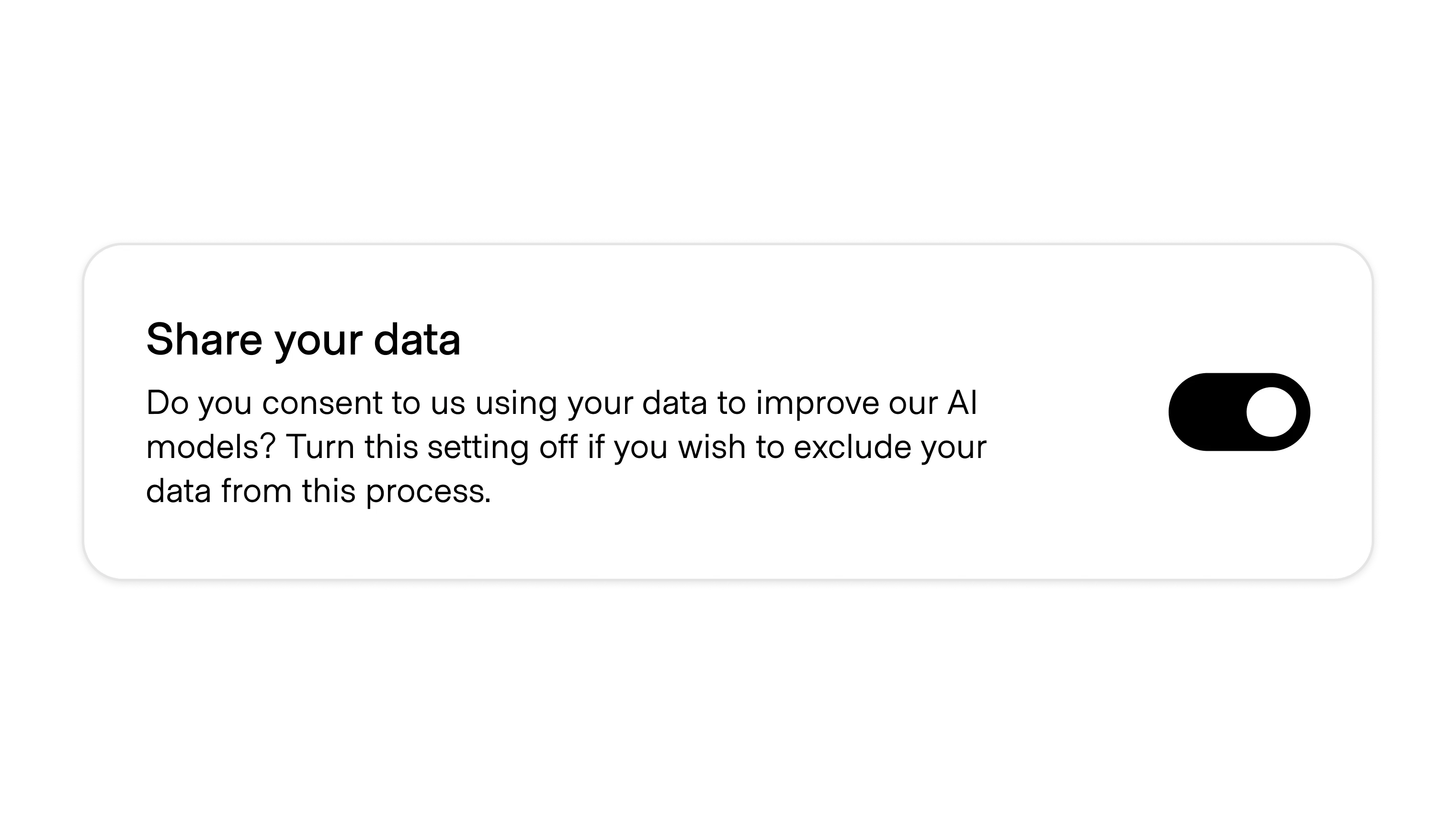
The pattern is generally the same in all uses: located in the user or company settings, a pithy statement about the need to improve the company's models for the benefit of all is paired with an on/off toggle.
Where its interface is consistent, the principles of interaction vary.
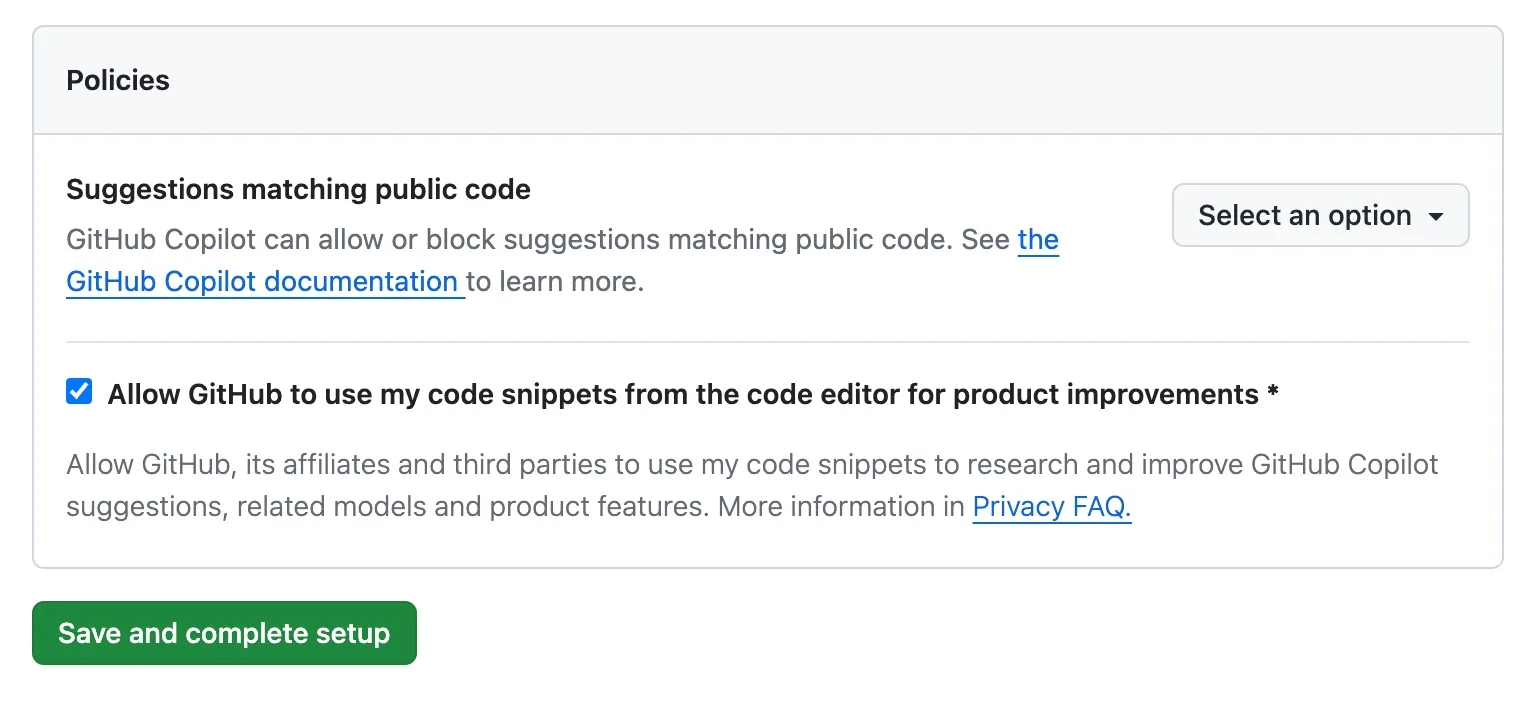
Most commonly, this setting defaults to "on." This is the case for ChatGPT, Substack, GitHub, and many other big players in the space.
Notably, when Figma announced their AI features at their Config conference in 2024, they took the approach of defaulting the option to "off." This could signal a departure from the norm towards customer-first defaults.

In many cases, the option to opt out of sharing your data or your company's data is only available on premium plans. Free users may never even see the setting, and won't be aware of the tradeoff.
This makes sense commercially, as the servers to run AI are expensive, so free users pay in the form of their data. As legislation related to AI becomes more concrete, we should expect to see pressure on this approach.
As Enterprise-grade accounts roll out across AI platforms, settings like this are being placed within the admin settings instead of within individual settings. Figma offers a good example of this approach. This is logically so that company admins don't have to rely on the discretion of employees to follow their standard security policies.
Some companies take this a step forward and fully guarantee a private experience. Limitless.ai doesn't include this setting because it doesn't train models with user data, and explicitly calls out in its privacy policy that it does not allow any third-party partners to use their users' data to train models either.
If you take this approach, you might want to include these details in your settings panel as well so that users don't think the lack of the setting relates to lack of privacy, when the opposite is true.