As AI becomes more prolific, it's increasingly important for people and for platforms to be able to differentiate between generated content and human-created content.
For consumers, this helps you sort through the bombardment of online content with more confidence and agency.
For creators, this protects the rights of your content from reproduction and counterfeits.
For researchers and platform owners, this protects the quality of the inputs into your work.
Watermarks help us by adding or identifying tracers into text, images, sounds, and video when it's created digitally by a model.
[Note: For the sake of simplicity in terms, this will combine the two approaches of digital watermarking and content provenance into one term]
Watermark types
Overlay watermarks are visual symbols or text added superficially to the content as a post-processing technique. They can be added automatically by the generative engine, or by the platforms where the content is uploaded. Overlay watermarks are not integrated into the structure of the content and can therefore be easily removed.
Steganographic watermarks embed patterns into the content that are imperceptible to humans. These might include subtle changes to pixels in video and images, additional spaces in text, or slight note changes in audio files. While slightly better protected than overlay watermarks, these can be masked intentionally or by bad actors through small changes to the file such as adding a Gaussian blur.
Machine learning watermarks use a new approach that relies on machine learning models to add a distinct key to the content that can only be read by other models. This is the process Google is using in their SynthID approach. They are stronger than the first two types, but can be degraded as the image is modified.
Statistical watermarks are random patterns injected into the image, audio, or text by the generator itself. While still impacting the content at the surface level (and not the foundational structure of the content), the randomness of this approach makes it far more difficult to crack or mask, especially for the average use.
Compared to content provenance
This alternative approach embeds data into the origin (or provenance) of the content itself, creating a digital fingerprint on the content's metadata. Content provenance requires the cooperation of content generators and digital platforms to create and enforce these standards.
Many large tech platforms have signed onto a pledge to incorporate standards developed by the Coalition for Content Provenance and Authenticity (C2PA), which defines a common format that cannot be tampered with without leaving traces of manipulation. This data could then be read by any platform that adopts the protocol, including the full history of modifications.
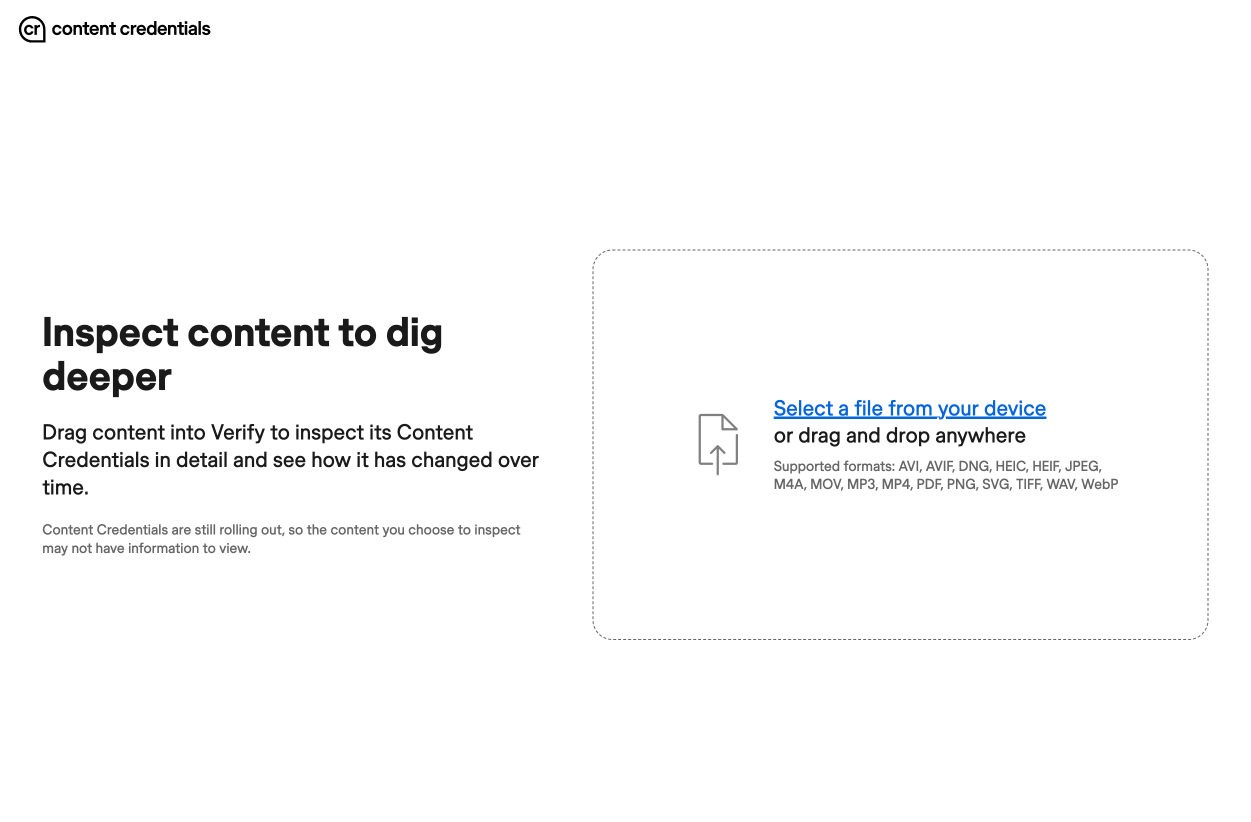
The Content Credentials Verifier allows you to upload content and see what watermarks are embedded in its metadata
Regulatory landscape
Early steps are being taken by many governments to enforce watermarks in both scenarios.
China requires source-generated watermarks, as well as the footprint pattern of including metadata in the filename when downloaded.
The European Union's AI Act imposes similar standards regarding labeling generated content, and also imposes requirements on foundation models to ensure transparency and compliance with copyright law.
In the United States, a 2023 Executive Order established standards for watermarking and regulation, but requires action by Congress to codify these standards for enforcement.
The implications of this regulatory tapestry remain to be seen. If you are working on a foundational model or generative tool, you can prepare by developing principles and standards to evaluate the product experience. If you are working on a platform, think through how to label this content in different scenarios.
There is not a conventional approach established that mitigates the conflicting risk to this issue, and most likely it will need to be solved through a combination of regulation and source code. Additional innovation is being pursued through other means, like MIT's work on PhotoGuard, which essentially blocks generative tools from manipulating certain aspects of an image.
Designers can lean in to help establish human-centered principles and conventions, and carefully construct copy and caveats to help users be as informed as possible.
If you want to track the progress of this issue, here are some resources to get started:
Articles and Explainers
MIT Technology Review: Clair Leibowicz on the ways watermarks can (and cannot) instill trust in consumers
EU Parliament: Whitepaper on Generative AI and Watermarking
SynthID - Tool by Google intended to add watermarks to AI-generated content
Stable Signature - Technology by Meta to catch AI-generated content
Truepic: Platform technology enabling synthetic content identification using C2PA
Design considerations
Make watermark visibility user-centered. Do not assume one level of visibility fits all cases. Consumers may need clear overlays or labels, while creators and researchers may prefer invisible or metadata-level tracers. Match visibility to the audience and context.
Support both imperceptible and visible watermarks. Visible labels deter casual misuse and clarify origin. Invisible tracers, like embedded hashes or model fingerprints, provide forensic accountability. Combining both gives broader protection across the content lifecycle.
Provide context when surfacing watermarks. Users need to know not just that provenance data exists but what it means. Include metadata such as source model, generation time, applied edits, and verified publisher when available.
Standardize placement across surfaces. Keep watermarks details in predictable locations, such as a “Content Info” panel, metadata view, or hover state. Consistency reinforces recognition and reduces fatigue.
Balance regulation and choice. Where watermarking or provenance disclosure is mandated, comply fully. Elsewhere, offer creators options for when and how attribution is applied, while preserving baseline protection for consumers.
Use Citations when the concern is intellectual lineage, not authorship. Citations attribute ideas and sources, whereas watermarks authenticate authorship and originality.
When aiming to help users understand how content was produced, pair watermarks with Prompt details. Prompts make the generative process legible, while watermarks certify the output’s origin.
Examples
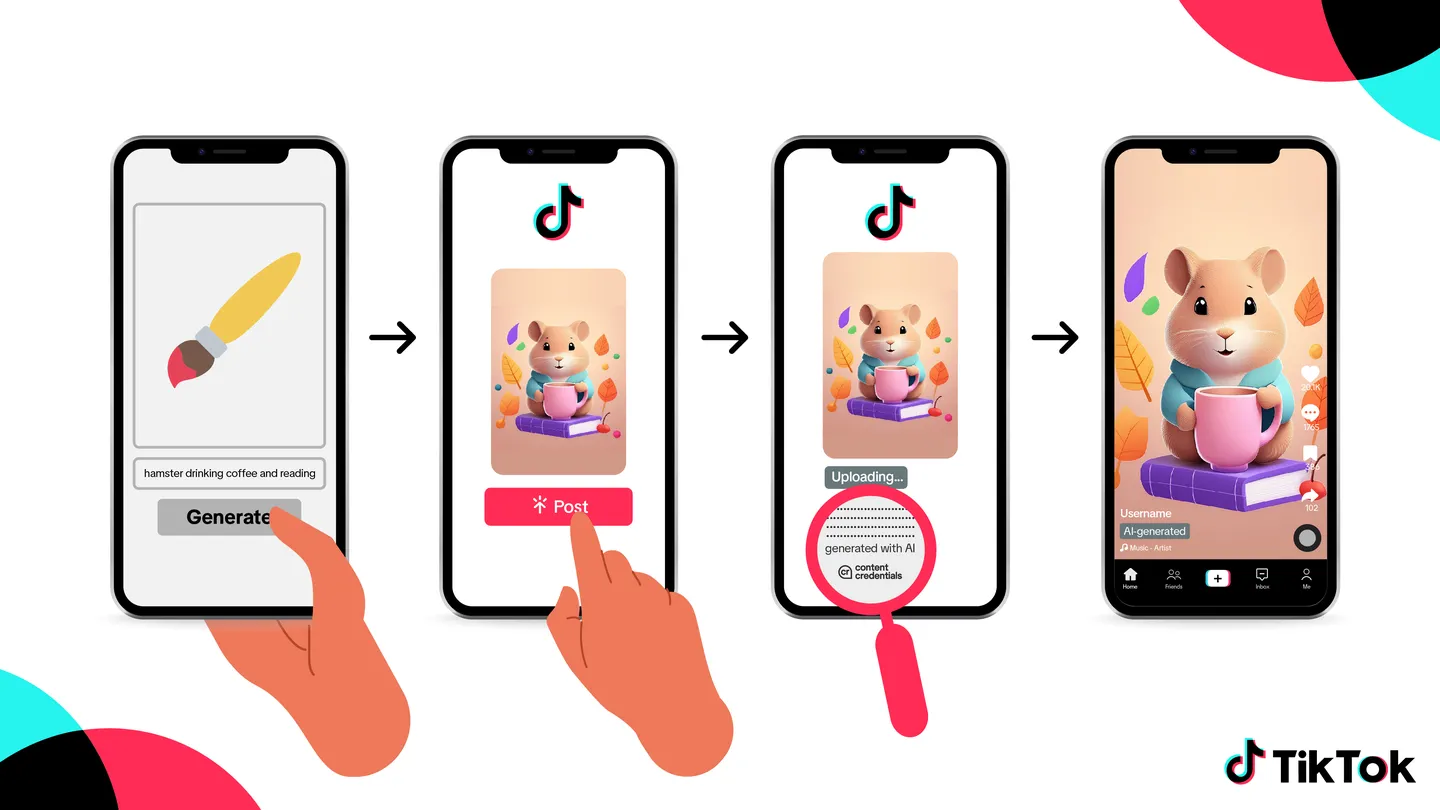
Adobe's Content Credentials protocol has been adopted by TikTok and other platforms with a shared icon intended to be a universal indicator of synthetic content
TikTok became the first social media company to support the Content Credentials Metadata tags for all content created on their platform.
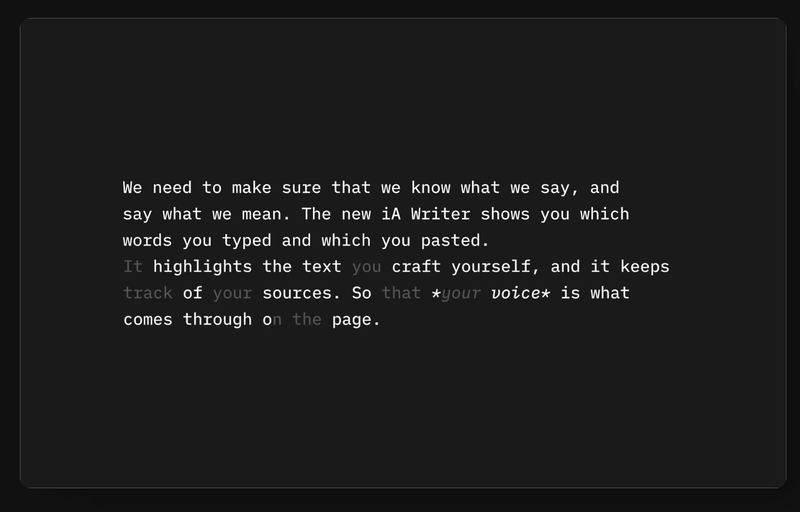
IA Writer offers an example of a tool proactively watermarking generated text, distinguishing it in grey from text actually authored by the user
Shutterstock labels AI-generated images within its gallery
Snap has developed its own proprietary symbol for AI content generated on its platform


-p-1600.webp)